Erzeugung von Indices aus Seiten-Merkmalen, Verwendung von Indices beim Export
Prinzipieller Ablauf bei einer einzelnen Seite
Im Folgenden soll der grundsätzliche Ablauf anhand einer (1) neu gescannten Seite erläutert werden.
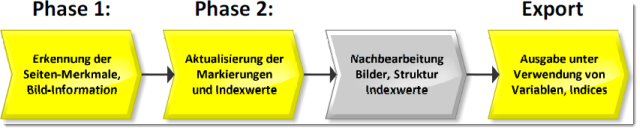
Phase 1:
Die soeben gescannte oder importierte Seite wird auf die in der Projektvorlage definierten Merkmale hin untersucht:
Zudem werden technische Bildinformationen, vom Scanner erkannte/übergebene Barcode-Werte und eine Kennzeichnung als Vorder-/Rückseite erfasst.
Achtung: Alle hier anfallenden Daten werden endgültig festgeschrieben und sind in der manuellen Stapelnachbearbeitung nicht mehr zu ändern!
Phase 2:
Obwohl alle inhaltlich relevanten Daten aus Phase 1 (Barcode-Werte, Textpassagen) über Variable abgefragt werden können, werden sie üblicherweise nicht zur Übergabe an Fremdsysteme oder zur Benamung von Ausgabedateien verwendet.
Stattdessen werden sie in Phase 2 in sogenannte Indexfelder überführt, welche einerseits eine spätere Korrektur der Daten erlauben und andererseits eine flexible Überprüfung / Validierung der Index-Werte und Formatierung ermöglichen, z.B. über Vorschlagslisten (lokal oder aus einer externen Datenbank), nach Datums-/Wertebereichen oder über reguläre Ausdrücke.
Wurde eine Barcode- Text- oder Leerseitenerkennung mit einer Dokumenttrennung gekoppelt, dann wird ein sog. Dokumenttrenner eingefügt. Falls eine als Leerseite erkannte Seite nicht sofort gelöscht wurde, wird stattdessen eine Löschvormerkung eingefügt. Dokumenten- und Seitenzähler werden dementsprechend angepasst.
Nachbearbeitung:
Die in Phase 2 erzeugten Indexwerte, Dokumententrenner und Löschmarkierungen können während einer manuellen Stapelnachbearbeitung verändert bzw. entfernt werden.
Export:
Die in Phase 2 befüllten Indexfelder können während des Exports entweder zur Benamung und zur Erzeugung eines Ausgabepfades für Bilddateien verwendet werden oder aber als Indexdatei direkt an Folgesysteme übermittelt werden.
Bei der Ausgabe der Bilddaten werden Löschmarkierungen berücksichtigt: Seiten mit einer Löschmarkierung werden beim seitenweisen Export ignoriert bzw. bei mehrseitigen Ausgabedateien übersprungen.
Ablauf beim Scannen mehrerer Seiten
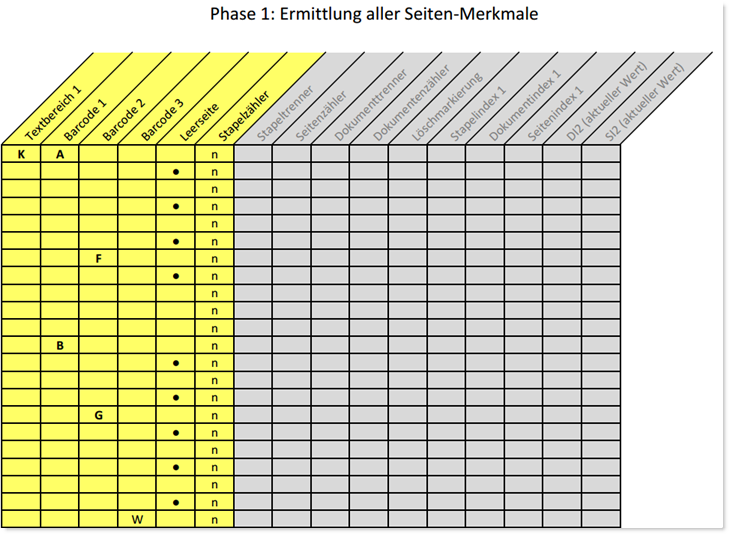
Der grundsätzliche Ablauf richtet sich auch hier nach dem oben gezeigten Phasenmodell. Allerdings gibt es innerhalb eines Stapels weitere Abhängigkeiten, welche sich am Beispiel der folgenden Tabelle aufzeigen lassen:
In diesem Modell repräsentiert jede Zeile eine gescannte bzw. importierte Seite (also ein Bild). Der Stapel füllt sich von der obersten, ersten Zeile (Seite) ausgehend nach unten. Die Verarbeitung aller Seiten verläuft von Links nach Rechts.
Phase 2 gestaltet sich im Großen und Ganzen wie erwartet, hat aber einige Besonderheiten:
Manuelle Nachbearbeitung
Sobald Seiten eines Stapels verschoben bzw. gelöscht werden, müssen Seitenzahlen, Dokumentenzähler und Indexwerte neu ermittelt werden. Das gleiche gilt für das Hinzufügen von Seiten und die Löschung bzw. das Verschieben von Dokumenttrennern.
CROSSCAP Enterprise gibt daher bei tiefgreifenden Veränderungen der Stapel-Struktur eine Warnung aus, insbesondere wenn hiervon Indexwerte betroffen werden.
Beim späteren Export eines Stapels wird der Stapel von der ersten Seite ausgehend sequentiell abgearbeitet (hier also von oben nach unten). Für die Benamung von Ausgabedateien und des Ausgabepfades verwendet dieses Beispiel Indexwerte, welche mit dem oben beschriebenen "Vortrag" der Indexwerte konfiguriert wurden.
In unserem Beispiel wird von einer Multi-Page Ausgabedatei ausgegangen (also von einer TIF oder PDF Multi-Document Datei). Die vom Exportprozess berücksichtigen Regeln bei der Erstellung der Ausgabedateien und der Verzeichnispfade sind wie folgt:
Bei der Ausgabe der Indexdatei wurde (in diesem Beispiel) der Indexwert für die Benamung der Indexdatei mit dem oben beschriebenen "Vortrag" der Indexwerte konfiguriert. Während des Exports wird daher nur eine einzige Indexdatei angelegt, diese bleibt während des gesamten Export-Prozesses geöffnet.
Die Indices, deren Werte in die Indexdatei geschrieben werden sollen, wurden mit der Option "Aktueller Barcode" konfiguriert. Diese Indices haben daher nur auf denjenigen Seiten einen Wert (und nur dann wird dieser Wert in die Indexdatei geschrieben), auf denen sich die entsprechenden Barcodes befinden.