
Die Konfigurationsmöglichkeiten im Detail:
Ausgabe
Vorschaufarbe Warnung
Markiert Zeichen oder Textpassagen, bei denen die Texterkennung nicht eindeutig war, in der gewünschten Farbe. Geben Sie entweder den passenden Farbcode (RGB Hex-Wert) händisch ein, oder benutzen Sie den Colour-Picker (erreichbar über das Erweiterungsmenü am Ende der Zeile).
Vorschaufarbe
Markiert gefundenen Text in der gewünschten Farbe. Dient zur optischen Unterscheidung bei mehreren Texterkennungs-Zonen. Geben Sie entweder den passenden Farbcode (RGB Hex-Wert) händisch ein, oder benutzen Sie den Colour-Picker (erreichbar über das Erweiterungsmenü am Ende der Zeile).
Text muss vorhanden sein
Im Regelfall überspringt die CROSSCAP Text-Erkennung kommentarlos alle Seiten oder Suchbereiche, auf denen kein Text zu finden ist. Die Aktivierung dieser Option (Ein) führt dazu, dass der Scan-Vorgang an solchen Stellen angehalten wird, um auf das Fehlen eines Textes hinzuweisen. Gleichzeitig erhalten Sie die Möglichkeit, den fehlenden Text händisch einzugeben.
Zeichenkette Filter
Erlaubt die Steuerung der Texterkennung anhand von Regulären Ausdrücken. Erkannter Text, der der Vergleichszeichenkette nicht entspricht, wird verworfen.
Das als Standard eingetragene Sternchen*
schränkt die Texterkennung nicht ein und lässt beliebigen Text passieren. Der Asterisk fungiert hier als sog. Wildcard-Zeichen.
Beginnt die Vergleichszeichenkette jedoch mit einem sog. Caret- oder Dachzeichen:
^
dann wird die Vergleichszeichenkette als Regulärer Ausdruck interpretiert. Ausführlichere Informationen zum Thema finden Sie im Kapitel Wissenswertes im Abschnitt Reguläre Ausdrücke.
Neues Dokument
Wird der in der Vergleichszeichenkette (oben) spezifizierte Text erkannt, dann wird an dieser Stelle ein Dokumenttrenner eingefügt und der Dokumentenzähler entsprechend heraufgesetzt.
Löschmarkierung setzen
Wird der in der Vergleichszeichenkette (oben) spezifizierte Text erkannt, wird das betroffene Bild mit einer Löschmarkierung versehen und nach dem Abschließen des Projekts gelöscht. Diese Seite wird nicht in der Ausgabedatei enthalten sein.
Eingeschaltet
Schaltet diese Funktion An oder Aus.
Im Gegensatz zu einer Löschung erhält die Deaktivierung dieser Funktion (Aus) alle hier gemachten Einstellungen, falls man diese Funktion bei späterer Gelegenheit wieder aufgreifen möchte.
Bildverarbeitung auf dem Server (nur in Verbindung mit CROSSCAP Enterprise)
Um CROSSCAP von rechenintensiven Bildbearbeitungsfunktionen zu entlasten und den Scan-Vorgang zu beschleunigen, können Bildbearbeitungsfunktionen selektiv an den CROSSCAP Server ausgelagert werden. Ist diese Option aktiviert, dann wird die Erledigung dieser Bildbearbeitungsfunktion vom Server übernommen und nach Abschluss des Scan-Vorgangs abgearbeitet.
Name
Vergeben Sie einen eindeutigen Namen für diese Konfiguration. Dieser Name wird später an anderer Stelle verwendet, um auf diese Texterkennungs-Konfiguration zuzugreifen. Wird kein eigener Name vergeben, nummeriert CROSSCAP mehrere Texterkennungs-Konfigurationen (z.B. "Texterkennung 1").
Filter
Bildvorbereitung
Die hier gelisteten Unterfunktionen erlauben eine temporäre Veränderung der gescannten Bilder, um die Voraussetzungen für die Texterkennung zu verbessern. Beachten Sie bitte, dass die hier angewendeten Bildbearbeitungsfunktionen keine dauerhafte Veränderung der gescannten Bilder hervorrufen, also in den Ausgabedateien nicht mehr zu sehen sind.
Die zur Verfügung stehenden Funktionen stellen eine Untermenge der allgemein verfügbaren Bildverarbeitungsfunktionen dar. Details zu den einzelnen Funktionen erfahren Sie im entsprechenden Abschnitt:
Verarbeitung auf Seite
Hier können Sie festlegen, auf welchen Seiten nach Text gesucht werden soll. Je mehr Sie hier die Suche einschränken, umso schneller wird die Verarbeitung, weil nicht mehr auf allen Seiten nach Text gesucht wird.
Mögliche Einstellungen sind:
Bitte beachten Sie:
Verarbeitung auf N-ter Seite
Nimmt die Texterkennung wiederkehrend auf jeder n-ten Seite des aktuellen Stapels oder auf jeder n-ten Seite des aktuellen Dokumentes vor, je nachdem, was unter Verarbeitung auf Seite (s.o.) hinterlegt wurde. Geben Sie hier die gewünschte Anzahl der Seiten ein.
Suchbereiche
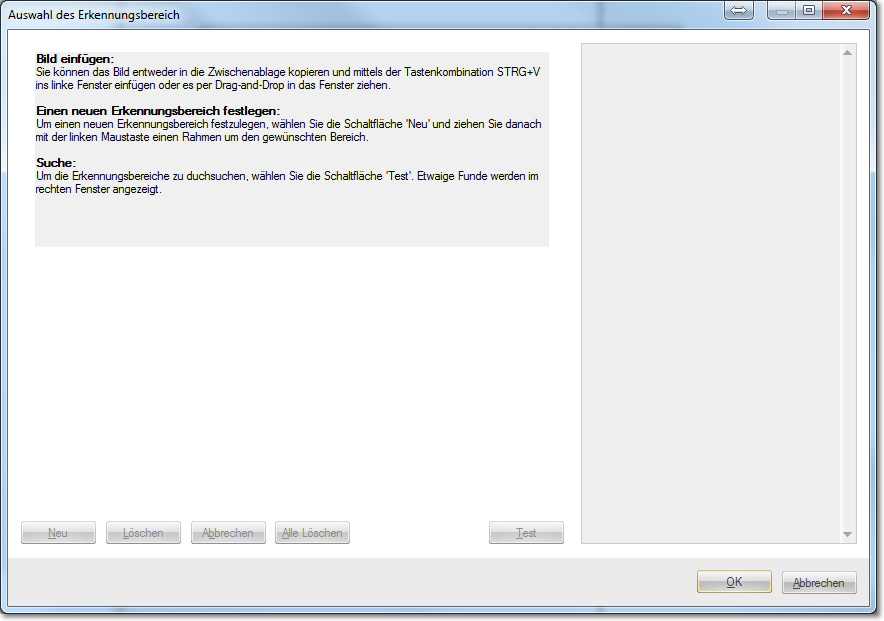
Hier können Sie festlegen, innerhalb welcher Bildbereiche Text erkannt werden soll. Mit dem Öffnen der Suchbereiche gelangen sie zu dem Dialog Auswahl des Erkennungsbereichs:
Um die entsprechenden Suchbereiche definieren zu können, muss ein zuvor gescanntes Image per Drag und Drop oder per Windows-Tastaturkürzel (z.B. Strg-V) in das Auswahlfenster kopiert werden. Die Dateiformate TIFF, GIFF, JPEG und PNG können hier verwendet werden.
Es wird empfohlen, die für die Definition der Suchbereiche verwendeten Bilder in einem gesonderten Ordner im Projektverzeichnis zu speichern und von dort aus in das Auswahlfenster zu kopieren. CROSSCAP speichert zwar den Link zum Image projektbezogen ab, aber wenn CROSSCAP bei erneutem Aufruf des Fensters Auswahl des Erkennungsbereichs das entsprechende Image nicht mehr findet, können auch die Erkennungsbereiche nicht mehr angezeigt werden.
Um einen Bereich zu definieren ist erst die Taste „Neu“ anzuklicken und dann mit der Maus (mit gedrückter linker Maustaste) ein entsprechendes Fenster aufziehen. Das jeweils angewählte Auswahlfenster kann in Größe und Position geändert werden oder über die Taste „Löschen“ gelöscht werden. Mit der Taste „Test“ werden die definierten Bereiche ausgelesen und das Ergebnis im rechten Fensterbereich angezeigt. Der erkannte Text ist nun unter dem Namen und der entsprechenden Bereichsnummer in der Variable Texterkennungstext aufrufbar, z.B. zu Zwecken der Indexierung oder als Dateiname.


Nur Patchcodeseiten
Schränkt die Suche nach Text auf Seiten mit Patchcodes ein. Folgende Optionen sind möglich:
S/W-Seiten ignorieren, Grauton-Seiten ignorieren, Farbseiten ignorieren
Die drei Filter S/W-Seiten ignorieren, Grauton-Seiten ignorieren, Farbseiten ignorieren beziehen sich auf den sog. Multistream Modus. Sofern Multistream nicht aktiv ist, sollten diese Filter ausgeschaltet bleiben. Ansonsten schalten Sie bitte ein oder zwei dieser Filter ein (An), um die Suche auf nicht relevanten Bildtypen zu unterbinden (dies erspart unnütze CPU-Last). Bitte beachten Sie, dass die Anwahl aller drei Typen dem völligen Abschalten der Barcode-Suche entspricht.
Leerseiten ignorieren
Wenn An eingestellt ist, werden Leerseiten nicht bearbeitet (dies erspart unnütze CPU-Last).
Ignoriere erste Dokumentseite
Wenn diese Option aktiviert ist, dann werden Seiten, die den Beginn eines neuen Dokuments ausgelöst haben (z.B. Patchcode-Blätter) von dieser Funktion nicht berücksichtigt.
Ignoriere Deckseiten
Wurden für diese Projektvorlage Deckblätter spezifiziert, werden diese nicht berücksichtigt.

Texterkennung
Nur Zahlen
Verbessert die Erkennung von Ziffern, indem typische Erkennungsfehler korrigiert werden:
'Ü'>'0', 'O'>'0', 'I'>'1', 'l'>'1', 'B'>'8', 'ó'>'6', '?'>'7'
Zeichenliste
Zeichen in dieser Liste können bei Bedarf entfernt oder ersetzt werden. Die gewünschten Zeichen werden ohne Trennzeichen nacheinander eingegeben. Diese Liste wird von der Funktion Umgang mit Steuerzeichen (siehe unten) verwendet. Wird sie dort nicht ausgewählt, hat diese Liste keine Auswirkungen.
Umgang mit Steuerzeichen
Legt fest, wie mit Steuerzeichen (nicht-druckbare Zeichen wie z.B. Zeilenschaltungen oder Tabulatoren) und den Zeichen aus der Zeichenliste (oben) zu verfahren ist:
Sprache
Die Texterkennungssprache muss an die Sprache Ihrer Dokumente angeglichen werden. Stellen Sie die Sprache also passend zu Ihren Dokumenten ein, um eine gute Erkennungsrate zu erreichen.
Geraderücken
Stellt das Bild automatisch gerade. Die Texterkennung erreicht hierdurch im Regelfall ein deutlich besseres Erkennungsergebnis. Schalten Sie diese Funktion also möglichst immer ein.
