You may configure the CROSSCAP Enterprise text recognition engine to process specific areas within images (zonal OCR). Retrieved text may then be filtered and passed on as index information (to external systems) or used for control purposes (within a batch).

Properties of OCR

Numbers only
If activated (checkbox ticked), this option will remove all letters from recognized text and let only numbers pass through.
Character list
Characters in this list can be removed from recognized text, or replaced with a dummy character. The characters to be replaced/removed are entered into this list without any delimiters, one after another. This list is only used by the Control characters option, below.
Preview color warning
Will highlight any text not properly recognised by the CROSSCAP Enterprise OCR engine with the color specified. Either enter the colour code manually (RGB hex value) or use the colour picker applet, to the right of the input field.
Preview color
Will highlight any recognizable text in the color specified. Also serves as a means of differentiation, if multiple OCR functions have been defined. Either enter the colour code manually (RGB hex value) or use the colour picker applet, to the right of the input field.
Control characters
Specifies how control characters (non-printable characters such a carriage returns) or characters from the Character list (see above) are treated:
Page processing
Limits the search for text to certain pages (the better the search is restricted, the less system resources will be wasted and project execution will speed up). Possible choices are:
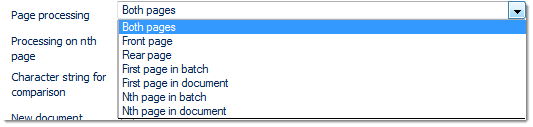
Please note: Nth page in project and Nth page in document operate in conjunction with the Processing on nth page setting described next ...
Processing on nth page
Periodically performs a search for text on each nth image of the current batch or the current document, depending on how Nth page processing was specified in the Page processing settings above. Enter the desired page count here.
Character string for comparison
Use this function to compare any text found with a set of filter criteria. Text not matching the filter conditions will be discarded.
The default entry is an asterisk:
*
and will accept any text.
If the Character string for comparison begins with a caret character, however:
^
then the entire filter string will be interpreted as a regular expression, which allows for flexible filtering.
For more and detailed information please refer to the section on Regular expressions, in the Appendix.
New document
Whenever CROSSCAP Enterprise detects any desired text, a document separator will be placed here and the document counter will be incremented by 1.
Language
Set the OCR language to the source language of your paper documents, for best recognition results.
Deskew
Deskew will vertically align images and thus improve text recognition results. It is recommended to activate this option, whenever possible.
Despeckle (available only with Abbyy FineReader)
Despeckle will automatically remove small blemishes / smudges.
Only patch code pages
Turns text recognition off (checkbox ticked) for all pages not containing patch codes.
Mark as empty page
If set to Off, images containing recognizable text will never be marked for deletion. If set to anything other than Off, images will be marked for deletion whenever CROSSCAP Enterprise detects recognizable text passages.
Setting Automatic will cause CROSSCAP Enterprise to omit all additional images usually associated with the image containing the recognized text (e.g. not only the front side, but also the reverse side of a page with text on it), from export.
In certain multistream scenarios, some scanners will not provide accurate metadata for scanned images, making it impossible for CROSSCAP Enterprise to intelligently decide which images to delete. As a work-around, you may specify a fixed number of subsequent images (1 to 5 pages) to be marked for deletion, instead.
Switched on
Turns text recognition on or off. Ticking the checkbox will turn text recognition on. Removing the checkmark will turn text recognition off but will preserve the settings made here, for later use (as opposed to simply deleting this definition).
Image processing on server
Detecting and recognising text requires substantial amounts of CPU capacity. In order to relieve CROSSCAP Scan-Clients from this task and speed up all other processing, image processing functions may be selectively transferred to the CROSSCAP Enterprise server.
If this option is activated (checkbox ticked), then execution of this function will be deferred and processed by the CROSSCAP Enterprise server, later on. Deferred image processing will occur during the pre-process workflow step (see chapter Getting started, section Workflow CROSSCAP Enterprise).
Please note: If any errors occur during image processing on the CROSSCAP Enterprise server, manual indexing (on the CROSSCAP Multi-Client) will be enforced (even if manual indexing was not specified in the project template).
Whenever image processing functions are transferred to the CROSSCAP Enterprise server, we generally recommend to arrange for separate quality checks and/or manual indexing, since there is no other chance to inspect (and possibly rectify) images processed by the server, prior to finalization.
Also, please take care to treat all interdependent image processing functions the same way, i.e. either run all of them on the CROSSCAP Enterprise server or have all of them processed by the CROSSCAP Scan-Client.
Name
You may label this particular text recognition definition with a name of your choice, which will make it easier to distinguish from any other text recognition setups created. If no custom name is assigned here, CROSSCAP Enterprise will automatically enumerate text recognition definitions.
Ignore monochrome pages, Ignore gray scale pages, Ignore color pages
Specifically applies to multistream mode. If any of these three filters are set to on (checkbox ticked), text search and recognition is turned off for the respective page types. Please note that combining all three options Ignore monochrome pages, Ignore gray scale pages and Ignore color pages will effectively turn off text recognition all together, since there is nowhere left to search.
Ignore blank pages
Turns text search and recognition off (checkbox ticked) for all blank pages (reduces CPU-load).
Properties of Image preparation:
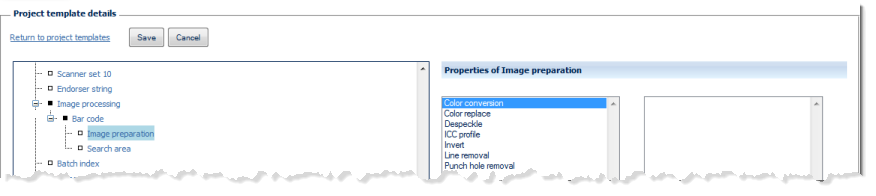
Selected image processing functions (listed below) are available for temporarily modifying images, prior to text recognition. Please note that any image processing specified here will not be applied to any of the finalized/exported images.
For details, please refer to respective sections in this chapter.
Properties of Detection areas

Search area
For each of the search areas defined, the exact location and dimension needs to be specified:
X & Y co-ordinates
The origin of this co-ordinate system is at the top left corner of an image. The x-value specifies the horizontal distance from the origin, the y-value specifies the vertical distance from the origin. Enter both co-ordinates as tenths of millimetres.
Width, Height
Enter width and heigth of the search area as tenths of millimetres.